| www.damir26.narod.ru |
|
| С открытым забралом! |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
|
Рекомендую посетить
 |
Надо отметить, что эта глава представлена в третьей редакции. Видимо настолько сложен оказался сам формат для освоения (у меня, по крайней мере). Конечно, для большинства пользователей хватает простого чтения pdf-файлов через родной вьювер Adobe Acrobat Reader. Я же этот формат возненавидел с момента нашего знакомства (как только у меня появились pdf-файлы в компьютере). Дело в том, что мне крайне было необходимо вытащить текст из этих файлов. Где-то это удавалось, но удача себя не оправдывала, поскольку строчки из абзацев, скопированные в буфер обмена, при вставке в Word представляли собой самостоятельные абзацы, то есть если слово переносилось на другую строчку, то перенесенное становилось самостоятельным словом, начинающим новый абзац. Word в таком случае зеленел от злости и краснел от бессилья, а вдобавок мог запросто вывалиться (есть у него такая особенность), хорошо, что в версиях, начиная с XP он мог перезапуститься с восстановлением. Это я описал случаи, когда было возможно извлечь текст из pdf-файла. Но были и такие, когда Acrobat сурово предупреждал - файл запоролен, копирование запрещено. В общем, полный абзац котёнку не будет больше испражняться. Нужен был хороший конвертер. Но прежде чем перейти к конвертации из pdf- файлов в другой формат я должен рассказать о том, как создавать pdf-файлы. Это будет логически закономерно. На всем рынке pdf-собираемых программ мне приглянулась абсолютно бесплатная прога CutePDF Printer. Право, на знаю, бесплатна ли она сейчас, но в 2003 году, по крайней мере, была таковой. Я ее нашел в одном из выпусков журнала "Мир ПК".
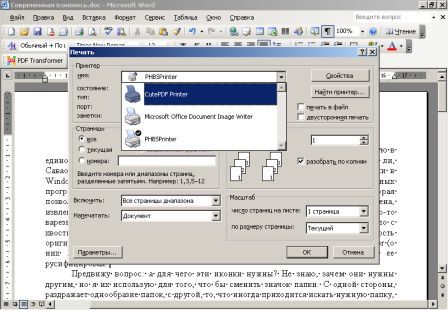
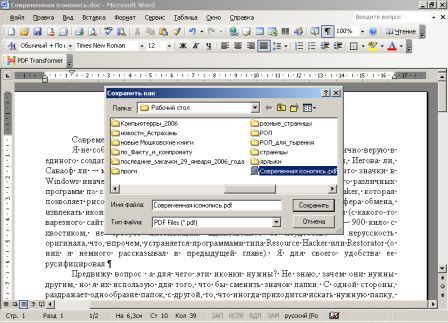
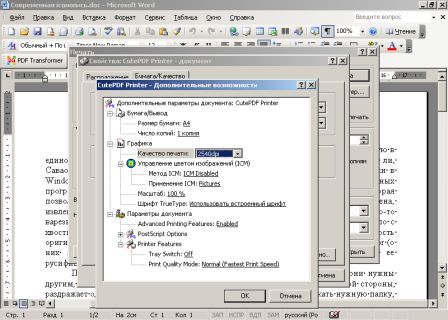
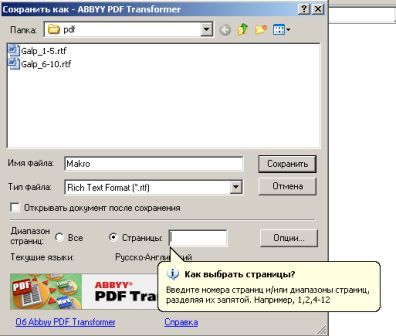
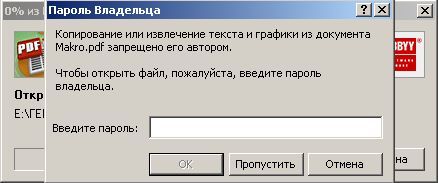
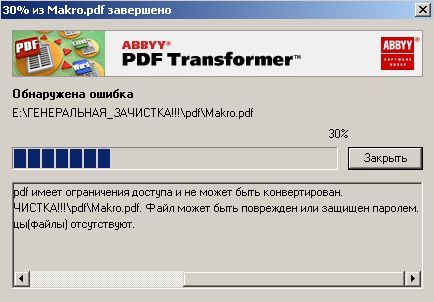
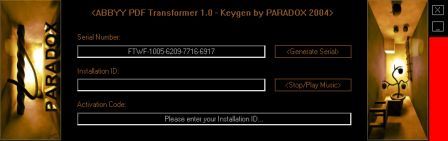
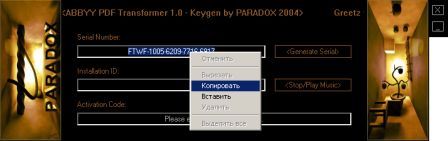
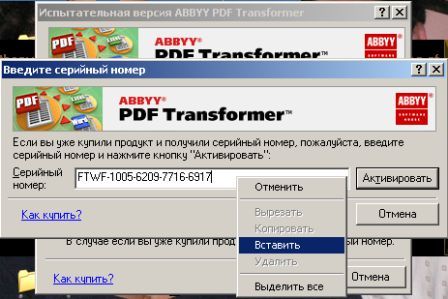
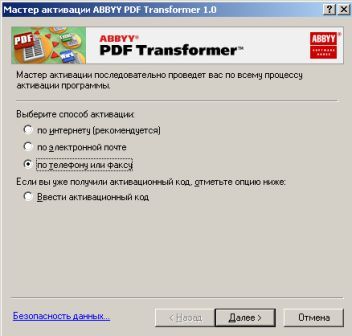
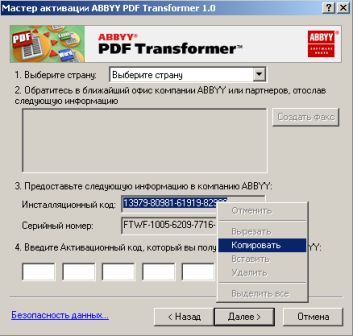
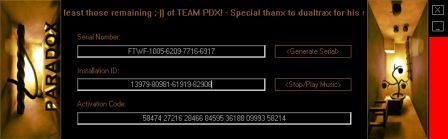
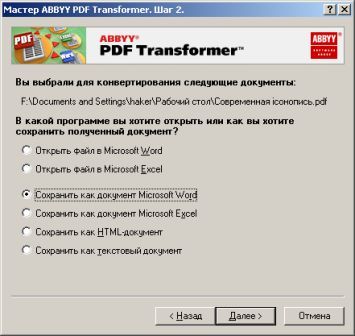
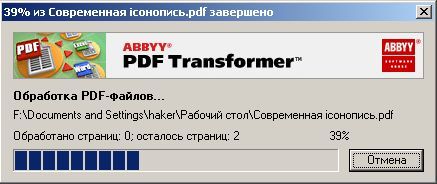
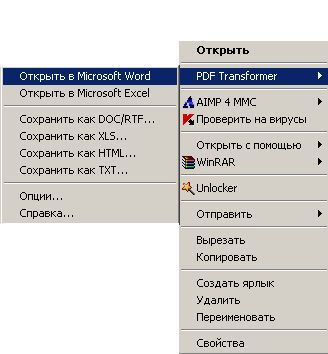
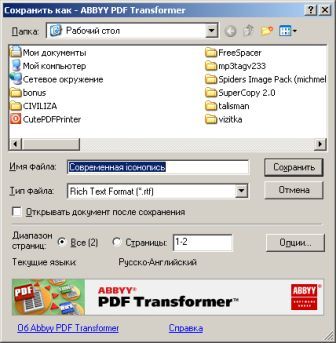
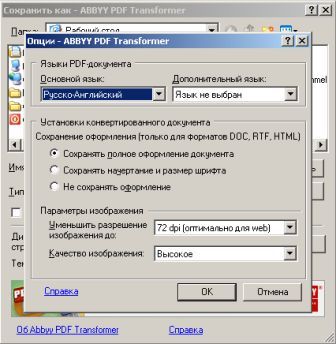
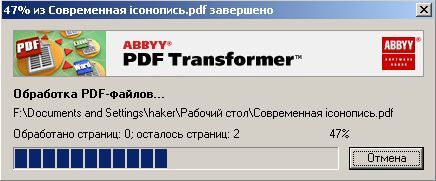
Собственного интерфейса у проги нет и представлена она как модель виртуального принтера. То есть, если вы создать pdf-файл в том приложении, которое имеет возможность вывода на печать, то достаточно из списка принтеров выбрать CutePDF Printer, после чего вылезет окно, предлагающее сохранить pdf-файл. Озаглавливаете файл и жмете "Сохранить" Запускается процесс виртуальной печати и pdf-файл будет создан. Единственный недостаток проги заключается в том, что с ее помощью нельзя установить пароль на файл. Впрочем, я это не отношу ни к достоинствам, ни к недостаткам, поскольку запороленный файл можно взломать. Ниже будет описана процедура взлома.. Итак, о создании pdf-файлов поговорили, теперь разговор о конвертации оных в другие удобоваримые форматы. Как я уже писал выше формат pdf оказался для меня очень сложным. Что только я не делал, что бы получить редактируемую информацию. Начинал же с того, что копировал содержимое экрана в буфер обмена (для этого на клаве есть ценная кнопочка "Print Screen") и вставлял содержимое в графический редактор "Paint", после чего обрезал элементы меню, попавшие в рисунок и сохранял полученное в формате tiff. Следующим шагом была оцифровка tiff-файла в "Fine Reader" и дальнейшее распознавание (так было в 4 и 5 версиях "Fine Reader"). После этого был процесс чистки полученного, иной раз плевался и предпочитал набрать текст, чем мучиться с распознанным: муторно и долго. Потом, кажется в "Fine Reader 6.0" стало возможным отправлять pdf-файлы для распознавания прямо в саму прогу. Процесс убыстрился, да и качество стало на выходе получше. Наконец программисты из ABBYY (файнридеровцы, как я их прозвал) создали автономный от "Fine Reader" продукт ABBYY PDF Transforrmer 1.0, механизм которого был направлен на тщательную конвертацию pdf-файлов. Прогу я скачал с сайта ABBYY и был немного раздосадован ее платностью. В триальной версии ее можно было запустить ограниченное количество раз и распознавалось за раз только три страницы (а у меня были тексты по 600 и более страниц). Я даже написал файнридеровцам письмо, что с обидой, что они не сделали продукт free для нищих россиян (хотя могли бы), в заключении я добавил, что обязательно найду кряк. Какая-то милая девушка из ABBYY мне написала ответ, что де за программные продукты надо платить, поскольку на этом строится деятельность фирмы, что пиратство (старая песня) не есть карашо, и что хакнутые проги ни есть карашо работать (еще одна старая песня). Дальше переписку с файнридеровцами я не продолжал, а отправился искать кряк, который быстро нашелся на пиратских порталах. Взломав программу я насытился в той части, касающуюся незапороленных pdf-файлов. Обрабатывая запороленные pdf прога настоятельно велела вводить пароль, который я, естественно, не знал.
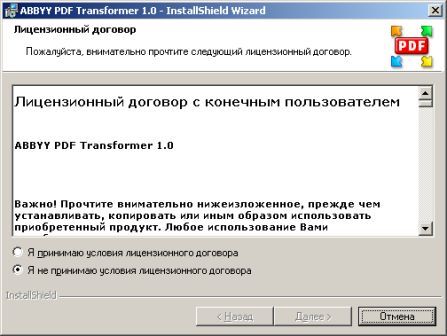
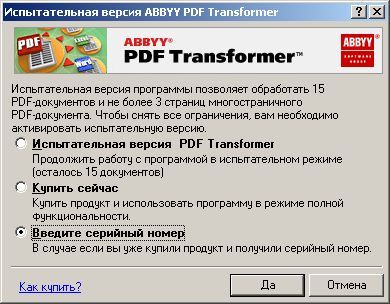
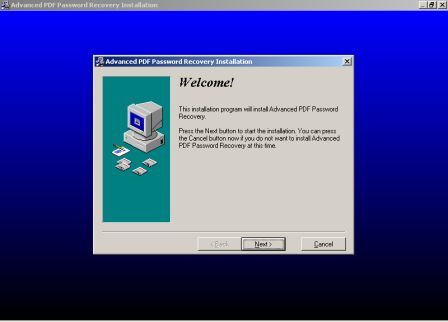
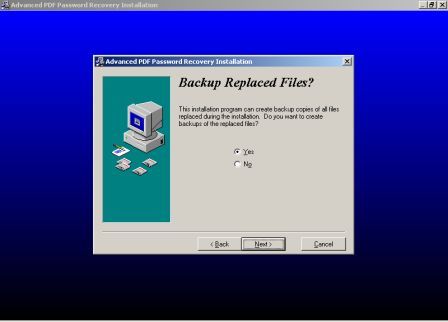
Пришлось знакомиться с рынком прог, снимающих защиту с файлов. Причем на каждый формат существует своя прога. Для pdf таковой оказалась "Advanced PDF Password Recovery". Скачав оную я опять был раздосадован триальнстью (полученный на выходе файл состоял из трех страниц, которые могли конвертироваться, а далее шли пустые листы, хорошо, что сам оригинал не пропадал, а сохранялся в виде bak-файла). Писать разработчикам я не стал, а отправился, правильно, к пиратам у которых и нашел вожделенную ломалку. История с пробитием бреши в защите pdf-файлов завершилась. Оставалось только найти что-нибудь acrobat-о-подобное для чтения самих pdf-файлов. Adobe Acrobat Reader от версии к версии стал расти как на дрожжах, пожирая при инсталляции до 70 мб дискового пространства. К этому прибавилась его медлительность при загрузке. В одном из бесконечных путешествий по Интернету я наткнулся на маленькую программку "Foxit Reader" и очень обрадовался ее способности быстро загружать pdf-файл . Конечно, с гиперссылкам, расположенными на pdf-файлах прога не работала, но зачастую это и не нужно. А CD-диски от компьютерных журналов, на которых присутствуют pdf-файлы, связанные между собой гиперссылками я смотрю не через автозапуск, а через простой пункт "открыть". В общем-то там все понятно. Иллюстрации Установка и взлом ABBYY PDF Trahsformer 1.0 Внимание! Кряк на сайте не выложен могу прислать письмом.
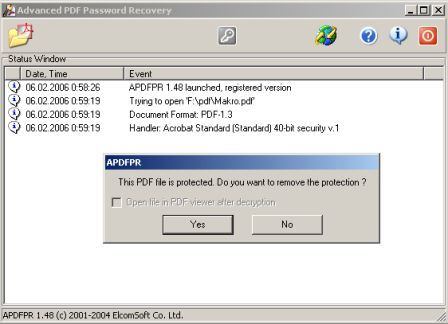
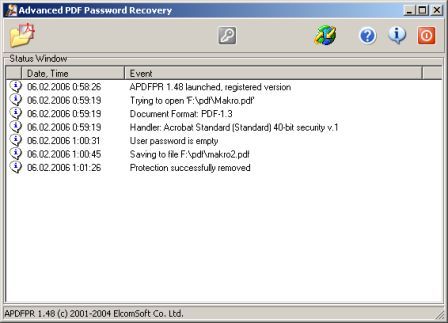
Установка и взлом "Advanced PDF Password Recovery" Внимание! Кряк на сайте не выложен могу прислать письмом.
Глава 4 / Содержание / Глава 6 |
|||||||||||
|
Сайт оптимизирован под разрешение 800x600 и браузер Internet Explorer
© 2004-2007 Концепция, дизайн, Дамир Шамарданов написать письмо |
||||||||||||